
tools
-
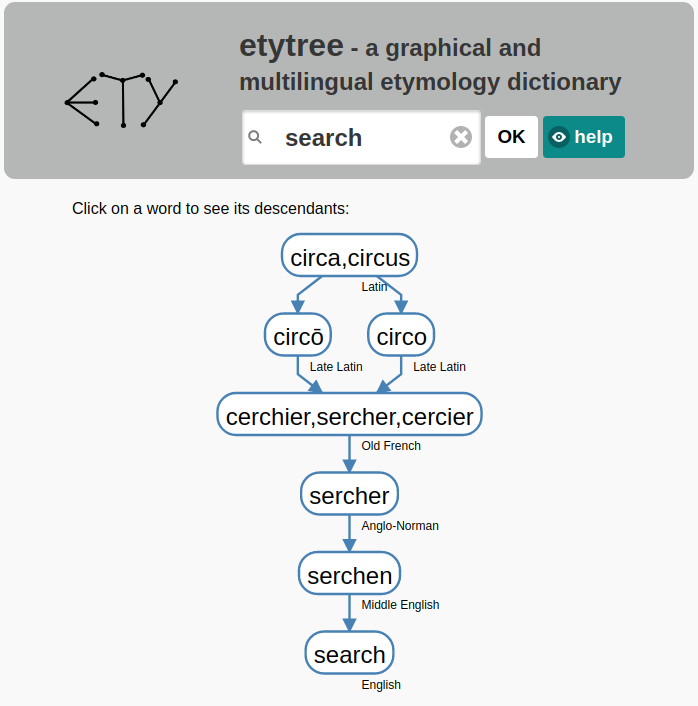
etytree
An interactive tool to visualize etymologies and find etymologically connected words + an RDF database of etymological connections extracted from the English Wiktionary. Developed with a Wikimedia Foundation individual engagement grant.

visualizations
-
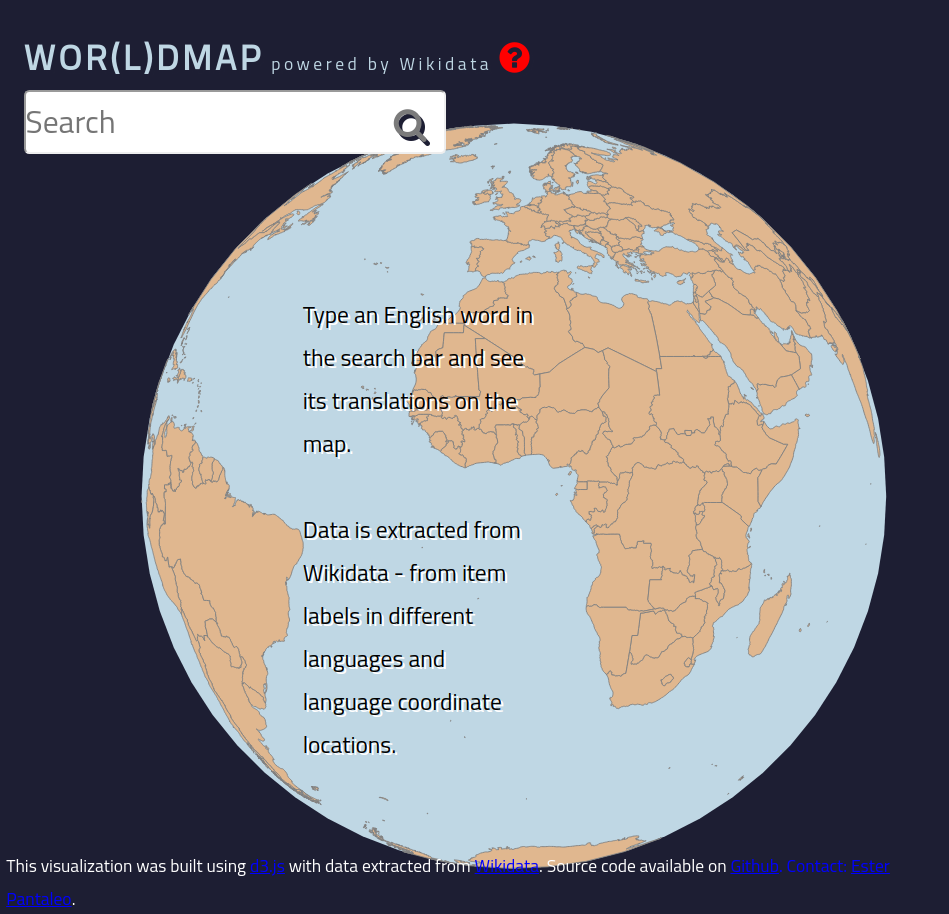
Wor(l)d Map using Wikidata
Search any English word and visualize its translations in any language on a world map. Data from Wikidata.

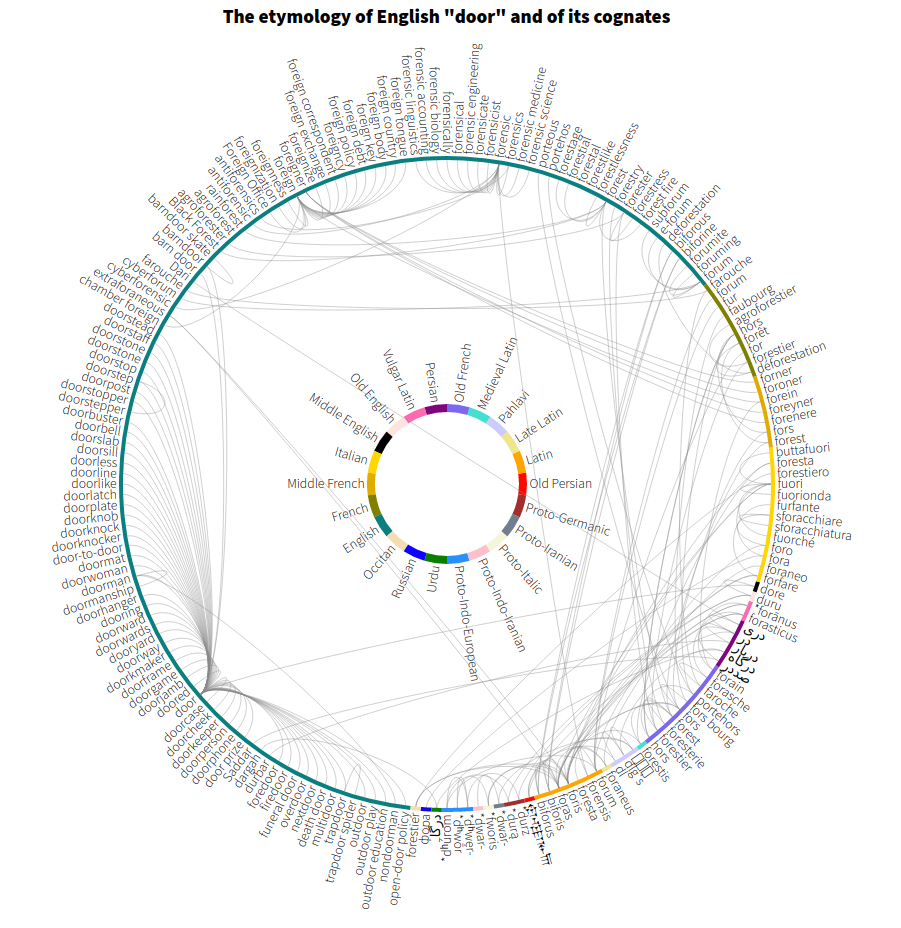
The etymology of door
A radial representation of all words etymologically related to the English word door as extracted from the English Wiktionary using the etytree tool and an RDF database of linked data.
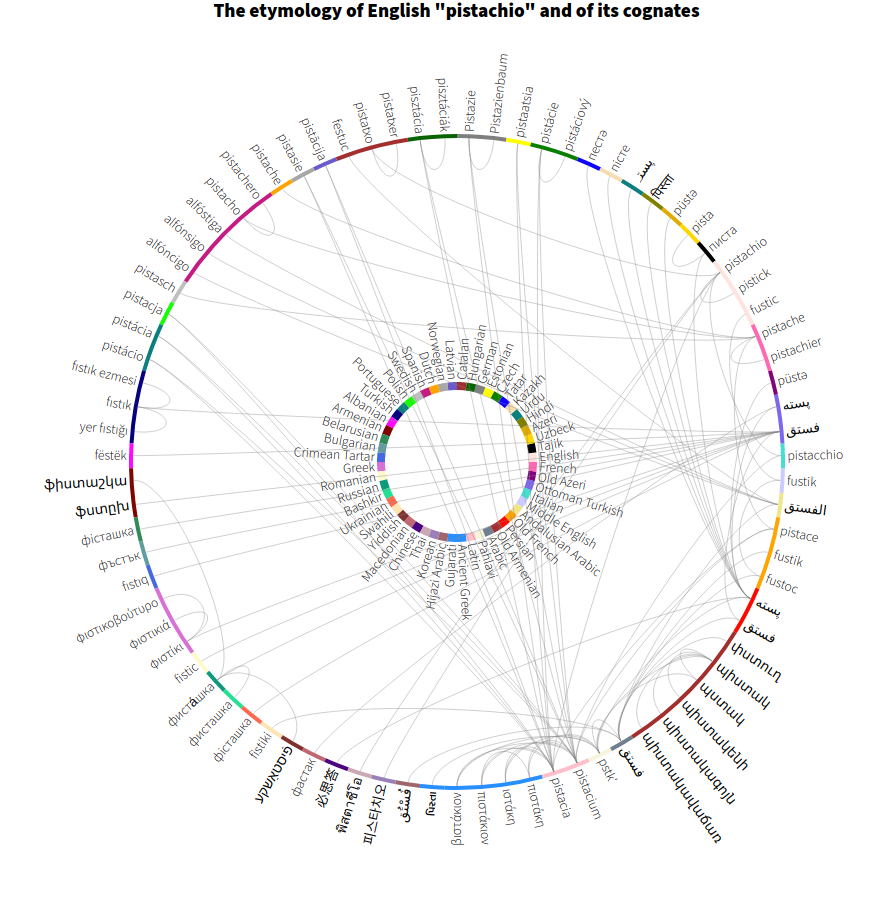
The etymology of pistachio
A radial representation of all words etymologically related to the English word pistachio as extracted from the English Wiktionary using the etytree tool and an RDF database of linked data.
ANPR dashboard
A real time interactive dashboard showing progress in the construction of a National Resident Population Register. Developed for the Digital Transformation Team of the Italian Government.

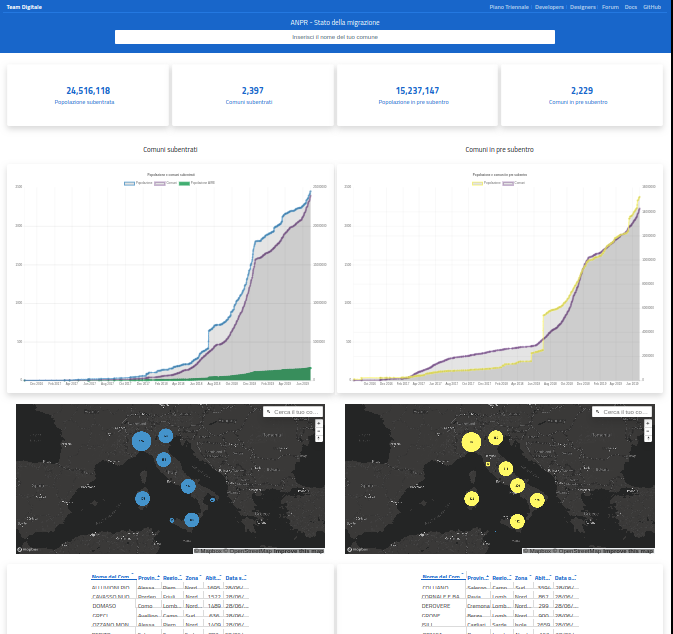
Star cluster evolution
An animated and interactive version of the HR diagram that evolves in time from birth to an age of 5 billion years using simulated data of a cluster of 100-star similar to our Sun's birthplace and images from the World Wide Telescope. Made for the Adler Planetarium, Chicago.


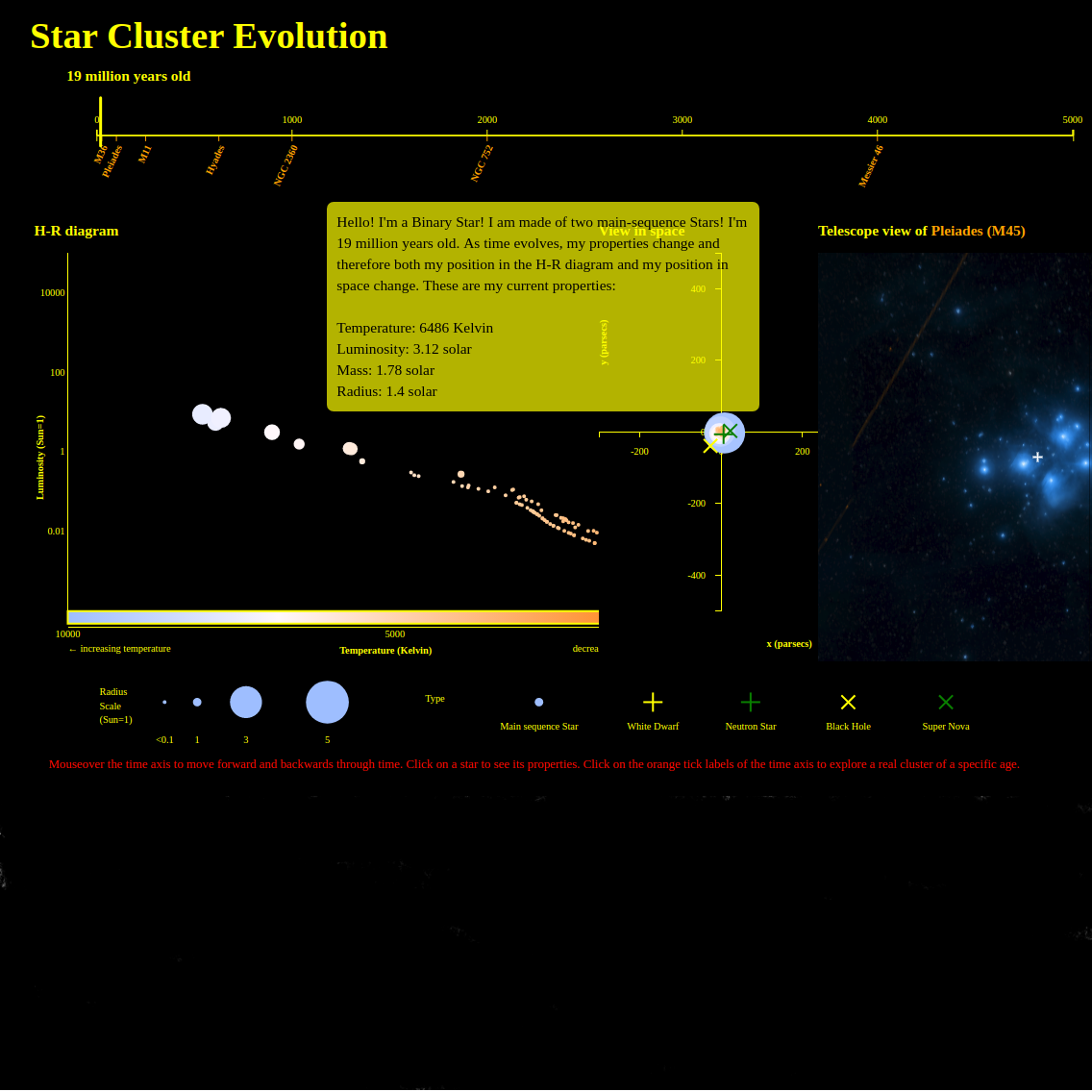
Flusso regionale studenti di Ateneo
An interactive visualization of the inbound, outbound, and stationary flow of Italian students per region, area of study, and sex using real data from MIUR. Made for the Digital Team of the Italian Government.
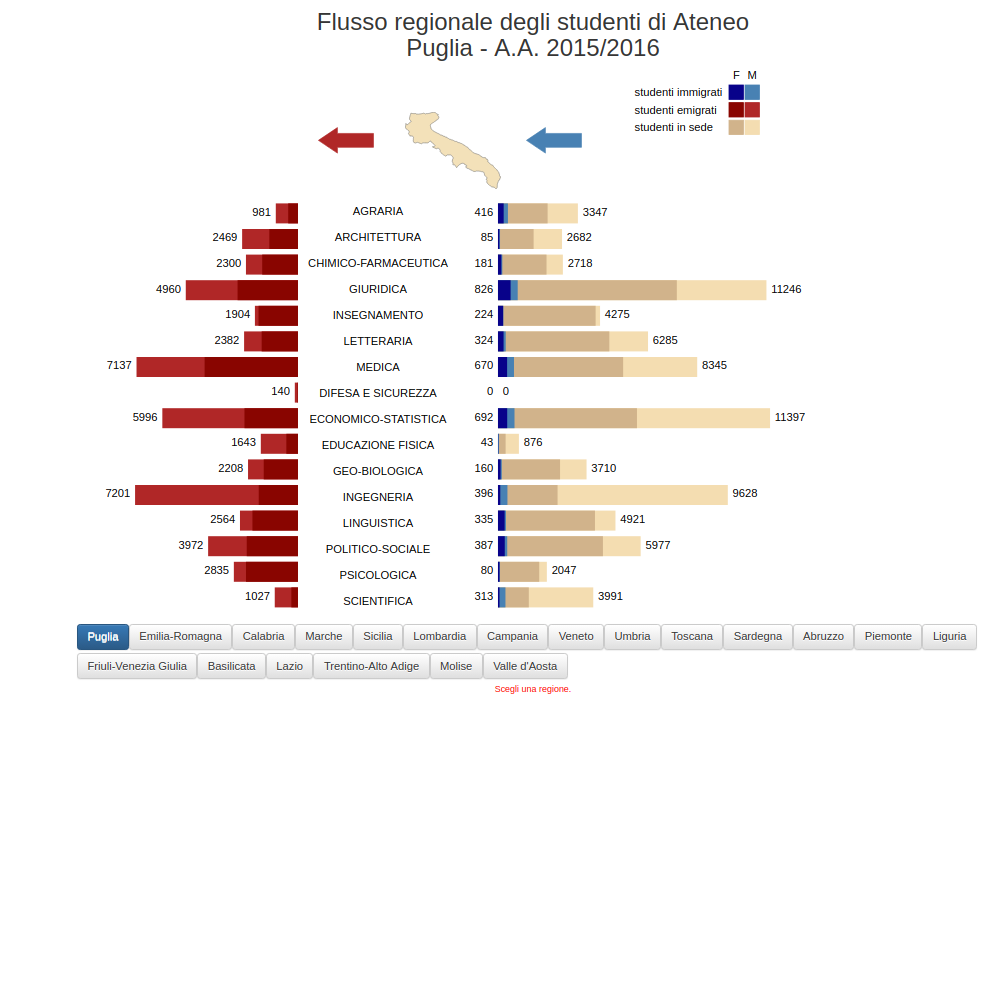
Mappa dei quartieri
An interactive dashboard to explore and compare different neighborhoods in major Italian cities using data from ISTAT and other public sources. Designed to work on desktop. Currently under development for the Digital Team of the Italian Government.
Infografica UNIBO
A visualization using open data on schools and courses of the University of Bologna. Currently under development for the Digital Team of the Italian Government.
Galicians toponyms
This poster shows how Galicia is interconnected with the rest of Europe through the etymology of its toponims.


research
-
altra
alternative transcripts estimation: a Bayesian method for simultaneous transcript reconstruction and abundance estimation with RNA-Seq data from multiple samples. Developed at the University of Chicago.

-
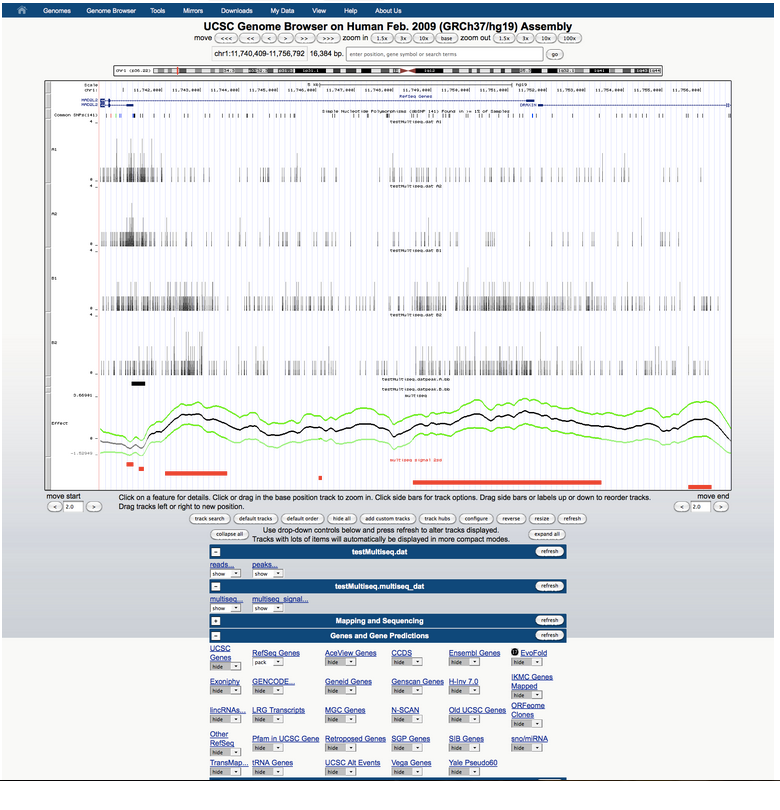
multiseq
Development of an R package for multiscale analysis, ongoing work in the Stephens lab at the University of Chicago. The embedded model considers data as an inhomogeneous Poisson process and tests for differences in underlying intensities using a Bayesian multi-scale model.
-
monomvn
Contributed to "Shrinkage Regression for Multivariate Inference with Missing Data, and an Application to Portfolio Balancing" published on Bayesian Anal. Vol.5, N.2 (2010), by extending the model to data with fat tails. Developed at the University of Cambridge.

Covariance estimation
Comparison of different portfolio optimization techniques "When do improved covariance matrix estimators enhance portfolio optimization? An empirical comparative study of nine estimators" published on Journal of Quant. Finance, Vol.11 (2011), 7.

Hausdorff clustering
Joint work on the development of a new clustering algorithm based on the Hausdorff distance, also applied to financial time series.

-
Tweets
Tweets by missipiaciut -
Blog posts
-
etytree, an interactive and multilingual etymology dictionary
Etytree has been so far my favorite project. I was coming back from the States after more than 4 years and I had some time to think of new projects. I had always wanted to have a tool to search for the etymology of a word in a specific (but any) language and display its etymological tree, i.e., the tree with its ancestors and cognate words, and how they are related. No such tool was available so I thought ... it would be very cool if I did it myself, since I had time.
I looked for data. The simplest source, I thought, is Wiktionary, which has dictionaries in multiple languages. However only the English Wiktionary was ready to be used as an automatic source of data, as it was one of the few with standardized Etymology sections. Nonetheless, the English Wiktionary is a dictionary of words in any language, in principle, with definitions in English. Also I saw that a few researchers had already developed tools to extract data from Wiktionary, including, among others who where less responsive, DBpedia and Gilles Sérasset from the University of Grenoble Alpes. The DBpedia project, although outstanding, wasn't maintaining the Wiktionary extraction tool. Prof. Sérasset, instead, showed great interest in the project and in a possible collaboration. I decided to collaborate with him.
The next step was looking for fundings. I contacted many different institutions and universities and then I found the individual engagement grant of the Wikimedia Foundations, whose purpose was to fund projects developed by individuals. I wrote a long and detailed grant, applied and went through a few interviews plus a relatively long process of community review. The people I encountered were enthusistic about the project and I got the funding!
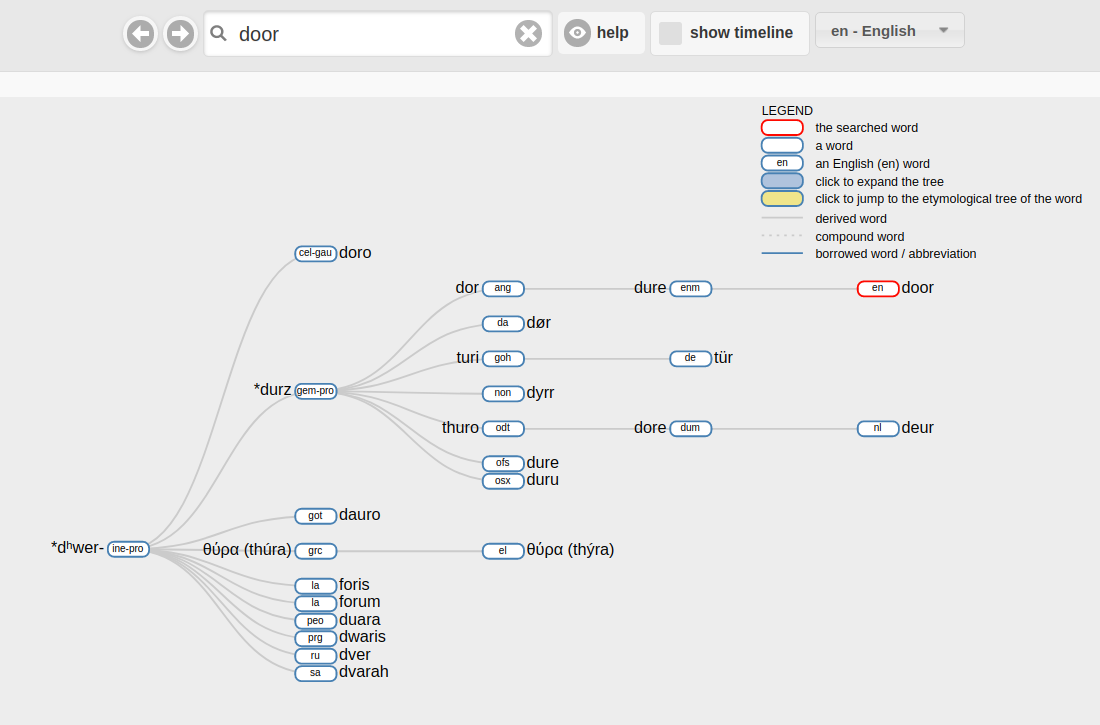 The original idea is shown here, where you can explore the proof of concept of the tool. The idea was to use hierarchical trees of etymological connections between words, and visualize on one page all cognates and how they are related in different languages. Also to add the possibility of visualizing the etymology on a time scale (see picture). I discovered how parseley and celery come from the same ancestor, and how pistachio is spelt differently in a number of languages. And how tear in English and lacrima (tear in Italian) are etymologically related, or how the word apricot took form. I could even find how some words in my dialect (Barese/Tarantino) are derived from Persian or French.
The original idea is shown here, where you can explore the proof of concept of the tool. The idea was to use hierarchical trees of etymological connections between words, and visualize on one page all cognates and how they are related in different languages. Also to add the possibility of visualizing the etymology on a time scale (see picture). I discovered how parseley and celery come from the same ancestor, and how pistachio is spelt differently in a number of languages. And how tear in English and lacrima (tear in Italian) are etymologically related, or how the word apricot took form. I could even find how some words in my dialect (Barese/Tarantino) are derived from Persian or French.
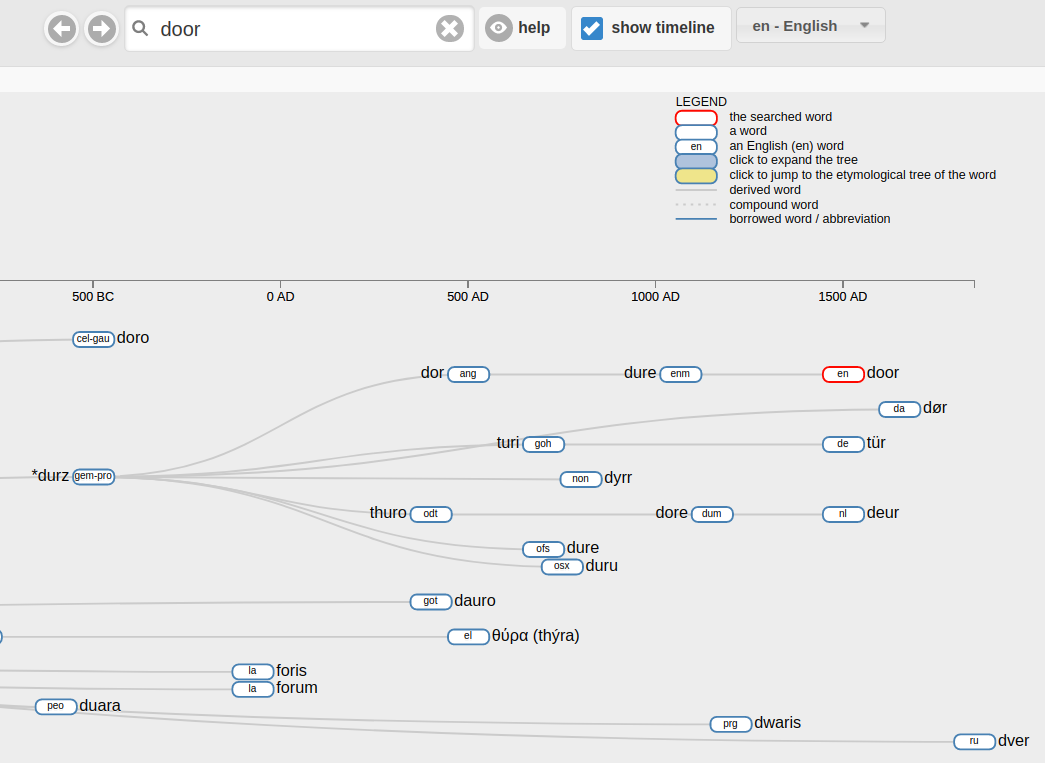 I was able to create an RDF database of etymological relationships containing more than 2 million links between words in almost 4000 languages from a million etymology sections in the English Wiktionary, building on prof.Sérasset's extraction tool. I expanded his tool to also extract etymology sections using complicated regular expressions. One difficulty I faced was homographs, words that are spelt the same but have different meanings. Obviously such words have different ancestors, thus representing two different nodes in the database. However it often happens that, when they are mentioned in Etymology sections by users, these words are not differentiated. So when parsing Etymology sections I was left with ambiguity: if the Etymology section reads "wordA derives from wordB" and wordB is not unique but has a homograph, which wordB does wordA derive from? While I could have uses semantics to brake this ambiguity (and not always), this would have complicated things much, so I decided to skip this problem for the moment, given that the number of homographs is relatively small, and use maybe semantics for disambiguation at a later time.
I was able to create an RDF database of etymological relationships containing more than 2 million links between words in almost 4000 languages from a million etymology sections in the English Wiktionary, building on prof.Sérasset's extraction tool. I expanded his tool to also extract etymology sections using complicated regular expressions. One difficulty I faced was homographs, words that are spelt the same but have different meanings. Obviously such words have different ancestors, thus representing two different nodes in the database. However it often happens that, when they are mentioned in Etymology sections by users, these words are not differentiated. So when parsing Etymology sections I was left with ambiguity: if the Etymology section reads "wordA derives from wordB" and wordB is not unique but has a homograph, which wordB does wordA derive from? While I could have uses semantics to brake this ambiguity (and not always), this would have complicated things much, so I decided to skip this problem for the moment, given that the number of homographs is relatively small, and use maybe semantics for disambiguation at a later time.
A lot of interests insights can be gained by looking at database statistics. For instance it is interesting to see (and it makes perfect sense) that the most connected entries in the database are English -ly (11156), un- (8822), non- (7872), -ness (7295), -er (6342), -ic (3357), -like, -able, -less, -y, followed by Hungarian -ok-,-ek-,-k-, Italian -mente, -ità, Finnish -sti, German Shule, Haus, Stein, Holz, Sprache and English water, back, head, work, wood. Also it is possible to extract information like how many Italian words derive from Latin, Ancient Greek, French, English, Arabic, Spanish or other languages.
Once I had built a database, I started working on the visualization. I realized how trees were not really trees but graphs, and complex geometries were showing, because of typos, extraction errors, homograpy, inconsistency between Etymology sections of different words etymologically connected. At the same time, I was fascinated by the graphs I could build and by the many connections I would discover between words. Also I could discover new words, in other languages, that sounded similar to words I knew and that had a common ancestor. Fascinating.
For all these reasons I switched from a hierarchical representation (using trees), to a graph view, which complicated things because there isn't a way to easily plot directed graphs and to plot graph nodes from left to right following the direction of the links from source to target. Also etytree graphs are very big (think of the tree for the English word man, and how many descendants the word man has). Incorrect links also cause graphs that are in principle separated to be connected which aggravates the problem. I released a version in which a user can visualize the graph of ancestors of a word in any language (if it is available in the database) and also click on any word in this graph and see the list of all available descendants of that word, grouped by language.
Right now I'm trying to improve the visualization. I'm trying to use d3.js force field graph, and a force that is parallel to the y axes to align it to a time scale. I'll keep you posted on my progresses.
-